

〜NBA選手データでpandasの操作に慣れよう〜
pandasでデータを操ってみよう
前回の記事では、NBA APIを使って選手の成績を DataFrame という表形式で取得・表示する方法を学びました。今回はその続きとして、以下の3つの操作を学びます:
- 並べ替え(ソート)
- 抽出(フィルタリング)
- 集計(グルーピング・合計など)
これらは データ分析の基礎中の基礎です。NBAデータで手を動かしながらマスターしましょう!
使用データ:ケビン・デュラントのシーズン別スタッツ
今回は例としてケビン・デュラントのシーズン別のスタッツを使用していきます。まずはnba_apiとpandasを使ってデータを取得します。
from nba_api.stats.static import players
from nba_api.stats.endpoints import playercareerstats
import pandas as pd
# ケビン・デュラントのIDを取得
player = players.find_players_by_full_name("Kevin Durant")[0]
# キャリアスタッツを取得
career = playercareerstats.PlayerCareerStats(player_id=player['id'])
df = career.get_data_frames()[0]
# データの確認(上5行)
print(df.head())① 並べ替え(ソート)
KDが一番多く得点をしたシーズンを知りたい時は、シーズンごとの得点(PTS)が多い順に並べるといいでしょう。そんな時はこのようにします。
df_sorted = df.sort_values(by="PTS", ascending=False)
print(df_sorted[["SEASON_ID","TEAM_ABBREVIATION","PTS"]])🔸 解説
sort_values():指定した列で並び替えを行う関数by="PTS":並び替えの基準にする列(この場合は得点)ascending=False:降順(大きい順)に並び替える(※ascending=Trueにすれば昇順(小さい順)になります。)
df_sorted[[“SEASON_ID”, “PTS”]]の部分は、df_sortedと名付けたDataframeの、”SEASON_ID”、”TEAM_ABBREVIATION”、”PTS”と言う列だけ表示すると言う意味になります。
出力すると以下のようになります。
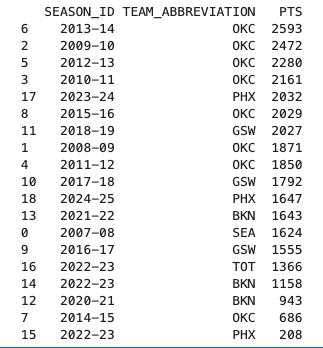
TEAM_ABBREVIATIONはチームの略語のことです。やはりKDが若手であったOKC時代が1位〜4位を占めてますね。5位はなんと35歳のシーズンのPHXでした。まさに衰え知らず。よく見ると、2022-23 シーズンが3つあり、TOT・BKN・PHXとそれぞれチーム名になっています。BKNはブルックリン・ネッツでPHXはフェニックス・サンズですが、TOTはどうやら合計のようです。シーズン中の移籍で複数在籍したチームが存在する場合は、このように合計の行も表示されるようになっています。
では、平均得点が一番高いシーズンはいつでしょうか?残念ながらこちらのデータには平均得点という列は存在しないので、シーズンの総得点÷試合数(GP)で求めていきましょう。
② 抽出(フィルタリング)
早速平均得点を算出したいですが、このままやると2022-23 シーズンが3つ算出されてしまいますね。合計列を除外するやり方と、OKC・PHXの2つを除外するやり方がありますが、他の選手の場合でも汎用性が高いようにTOTを除外することにします。そこで、TEAM_ABBREVIATIONがTOTではない行に限定してみましょう。
df_filtered = df[df["TEAM_ABBREVIATION"] != "TOT"]
print(df_filtered[["SEASON_ID","TEAM_ABBREVIATION","GP","PTS",]])🔸 解説
df[条件式]:DataFrameの中から、条件を満たす行だけを残す
df["TEAM_ABBREVIATION"] != "TOT"]:TEAM_ABBREVIATIONがTOTでない行だけにする。
Pythonの比較演算子一覧は以下になります。
✅比較演算子一覧(2つの値を比べる)
| 演算子 | 意味 | 例 | 結果 |
|---|---|---|---|
== | 等しい | 3 == 3 | True |
!= | 等しくない | 3 != 4 | True |
> | より大きい | 5 > 3 | True |
< | より小さい | 2 < 10 | True |
>= | 以上 | 5 >= 5 | True |
<= | 以下 | 3 <= 8 | True |
今回は”SEASON_ID”、”TEAM_ABBREVIATION”、”PTS”に加え、平均得点の算出のために”GP”(出場試合数)を追加しました。出力すると以下になります。
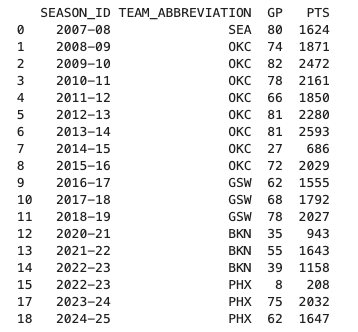
TOTの行が無くなったことが確認できます。それでは、シーズンごとに”GP”と”PTS”をまとめていきましょう。
③ 集計(合計・平均・グルーピング)
df_season_gp = df_filtered.groupby("SEASON_ID")[["GP","PTS"]].sum()
print(df_season_gp)🔸 解説
df.groupby("SEASON_ID"):SEASON_ID(シーズン)ごとにデータをまとめる[["GP", "PTS"]]:合計したい列を2つ指定(出場試合数と得点).sum():それぞれのシーズン単位で合計を出す
注意点として、集計したい列が複数あるときは [[ ]] の二重角かっこで書く必要があります。出力結果を確認してみましょう。
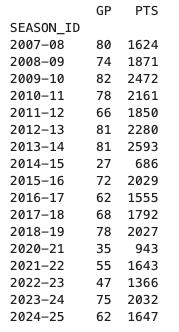
平均得点の計算に必要な、シーズンごとの出場試合数と得点を集計できました。それではいよいよ、平均得点を算出します。
df_season_gp["AVG_PTS"] = df_season_gp["PTS"] / df_season_gp["GP"]
df_season_gp_sorted = df_season_gp.sort_values(by= "AVG_PTS",ascending=False)
print(df_season_gp_sorted)こちらは、df_season_gp[“AVG_PTS”] で”AVG_PTS”という列名を新たに作成し、df_season_gp[“PTS”] / df_season_gp[“GP”]で計算式を書いています。そして先ほど学んだ並び替えで、平均得点が高いシーズンから並び替えました。結果はこちら。
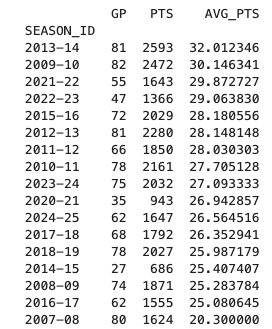
EPSNの公式サイトで合っているか確認してみましょう。問題なさそうです。
KDが得点王に輝いたのが2009-10、2010-11、2011-12、2013-14シーズンで、1位の2013-14シーズンはMVPも受賞しています。2009以降はキャリアでずっと25点以上平均しているというのは、本当に卓越した数字です。
まとめ
今回は並べ替え、抽出、集計を学びました。これらは今後必ず使用しますので、マスターしてしまいましょう!それでは次回は7:代表値を調べてみよう(平均・中央値・最頻値)に続きます。
コメントを残す