

~Pythonとは?NBAデータ分析にも使えるやさしいプログラミング言語~
「Pythonってなに?」
Python(パイソン)は、今いちばん注目されているプログラミング言語のひとつです。
シンプルで読みやすく、初心者にもやさしい。なのに、AI開発からWebサービス、データ分析まで、あらゆることに使われています。たとえば「NBAの選手データを分析したい」と思ったとき、Pythonならたった数行のコードでデータを取得して、すぐにグラフにすることができます。
これは他の言語ではなかなか難しい芸当です。
なぜPythonが人気なのか?
Pythonがここまで広まっている理由はいくつかあります。
- 書き方がシンプルで覚えやすい
英語のような自然な文法なので、初心者でも学びやすい。 - 活用できる分野が広い
Webアプリ開発、AI、データ分析、スクレイピング、業務自動化など、ジャンルを問わず使える。 - ライブラリが豊富
やりたいことを助けてくれる「ツール(ライブラリ)」が充実しています。たとえば、NBA公式データにアクセスできるnba_apiというライブラリも、そのひとつです。
Python × NBA_API:何ができるの?
PythonとNBA_APIを組み合わせると、こんなことができます:
- 特定の選手の過去の成績を自動で取得する
- チームごとのオフェンシブ・レーティングを分析する
- 「今季30得点以上を記録した選手」を抽出する
- データをグラフ化してブログや動画で紹介する
つまり、NBAが好きな人にとっては、Pythonがあるだけで自分だけの分析ツールが作れてしまうわけです。
どんなコードを書くの?
例えばステフィン・カリーのシーズンごとの3P成功数を知りたい!と思ったら以下のように書きます。
pip install nba_apifrom nba_api.stats.static import players
from nba_api.stats.endpoints import playercareerstats
# ステフィン・カリーの情報取得
player = players.find_players_by_full_name("Stephen Curry")[0]
career = playercareerstats.PlayerCareerStats(player_id=player['id'])
# データフレーム取得
df = career.get_data_frames()[0]
# シーズンと3ポイント成功数だけ表示
df_FG3M = df[["SEASON_ID", "FG3M"]]
print(df_FG3M)以上を実行すると以下がアウトプットされます。
SEASON_ID FG3M
0 2009-10 166
1 2010-11 151
2 2011-12 55
3 2012-13 272
4 2013-14 261
5 2014-15 286
6 2015-16 402
7 2016-17 324
8 2017-18 212
9 2018-19 354
10 2019-20 12
11 2020-21 337
12 2021-22 285
13 2022-23 273
14 2023-24 357
15 2024-25 311
SEASON_IDがシーズンで、FG3Mが各シーズンの3P成功数ですね。全体的に凄すぎますがその中でも2015-16シーズンの402本成功は別格ですね。流石の満票MVPです。
簡単にグラフを書くこともできます。
ステフィン・カリーと同じドラフトのスタープレイヤーといえばジェームズ・ハーデンですね。二人のシーズンごとの3P成功数の累計を折れ線グラフで見てみましょう。
from nba_api.stats.static import players
from nba_api.stats.endpoints import playercareerstats
import pandas as pd
import matplotlib.pyplot as plt
# 選手のID取得
def get_player_id(name):
return players.find_players_by_full_name(name)[0]['id']
# 累積3PMデータ取得
def get_cumulative_fg3m(player_name):
player_id = get_player_id(player_name)
career = playercareerstats.PlayerCareerStats(player_id=player_id)
df = career.get_data_frames()[0]
# "TOT"(複数チーム合算)を除外
df = df[~df["TEAM_ABBREVIATION"].str.contains("TOT", na=False)]
# シーズンごとに3PMを合計
df = df.groupby("SEASON_ID", as_index=False)[["FG3M"]].sum()
# 累積計算
df["CUM_FG3M"] = df["FG3M"].cumsum()
return df
# データ取得
curry_df = get_cumulative_fg3m("Stephen Curry")
harden_df = get_cumulative_fg3m("James Harden")
# グラフ描画
plt.figure(figsize=(10, 6))
plt.plot(curry_df["SEASON_ID"], curry_df["CUM_FG3M"], marker='o', label="Stephen Curry")
plt.plot(harden_df["SEASON_ID"], harden_df["CUM_FG3M"], marker='o', label="James Harden")
plt.title("Cumulative 3-Point Field Goals Made by Season")
plt.xlabel("Season")
plt.ylabel("Cumulative 3PM")
plt.xticks(rotation=45)
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
出力結果は以下になります。
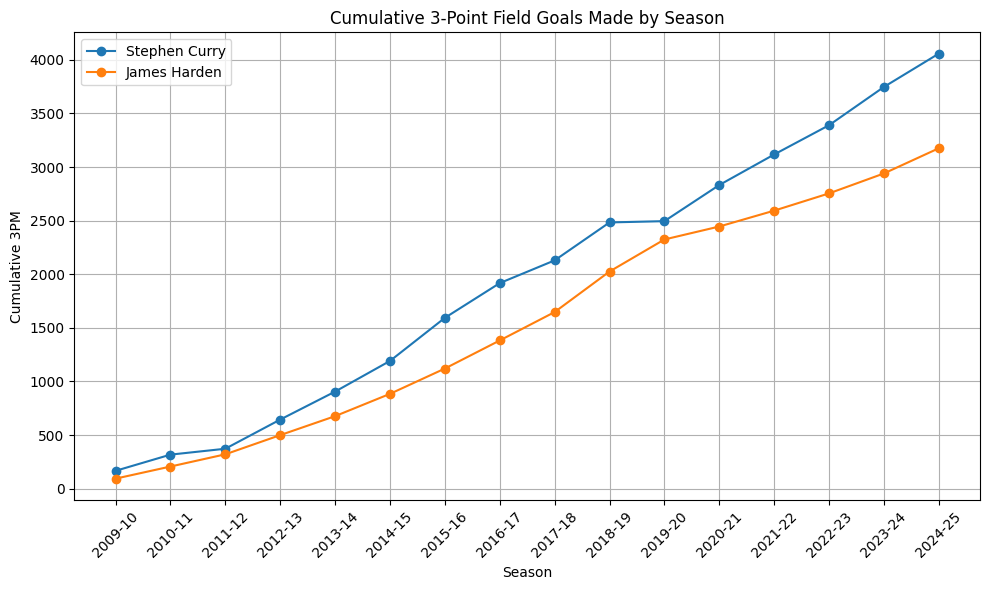
2024-25シーズン終了時点でカリーは4058本、ハーデンは3,175本の成功です。ハーデンは歴代2位ですが、1位のカリーとも1,000本近く差があるというのはカリーが史上最高のシューターであることを数値が物語っていますね。
上記のプログラムの内容は現段階で理解できなくても全く問題ございません!順を追って進めていけば基礎編終了後には自分でプログラムを記述できるようになっています。
Pythonは「NBAデータ分析」の最強パートナー
Pythonを使えば、NBAの膨大なデータを自分で取得し、分析し、発信できるようになります。
「ただのファン」から、「データを使って語れるファン」になるための第一歩として、Pythonは最強の相棒です。
Pythonってどうすれば使えるの?という方に向けて次回はJupyterLabを使って実際にPythonを動かしていきます。