

代表値ってなに?
データをざっくり「どんな傾向か」つかむときに便利なのが、代表値(だいひょうち)です。
主に次の3つがあります:
| 名前 | 意味 | 使いどころ |
|---|---|---|
| 平均(mean) | 全部の合計 ÷ 件数 | ざっくり「どのくらい」か知りたいとき |
| 中央値(median) | 並べたとき真ん中にくる値 | 外れ値の影響を受けにくい |
| 最頻値(mode) | 最もよく出てくる値 | 一番多い傾向を知りたいとき |
Shai Gilgeous-Alexander の実データで代表値を求めてみよう
2024-2025シーズンのMVPであるShai Gilgeous-Alexander (以下、シェイ)のレギュラーシーズンのスタッツを使用していきます。データの準備をしていきましょう。
from nba_api.stats.static import players
from nba_api.stats.endpoints import playergamelog
import pandas as pd
# 選手のIDを取得
shai = players.find_players_by_full_name("Shai Gilgeous-Alexander")[0]
player_id = shai['id']
# 引数(パラメータ)を設定して、Shai Gilgeous-Alexanderの2024-25シーズンのレギュラーシーズンスタッツを取得。
gamelog = playergamelog.PlayerGameLog(
player_id=player_id,
season='2024-25',
season_type_all_star='Regular Season'
)
df = gamelog.get_data_frames()[0]
ここで、playergamelog というエンドポイントが出てきました。playergamelog は、nba_api ライブラリの中でも非常によく使われるエンドポイントのひとつで、特定のNBA選手の試合ごとのスタッツ(Game Log)を取得するための機能です。playergamelog.PlayerGameLogでplayer_idにモジュールstaticのplayersを用いて取得した選手のIDを代入し(シェイのIDは22024)、seasonに取得したいシーズンを渡し、season_type_all_starにプレイオフやレギュラーシーズンなどの情報を渡します。
☑️引数(パラメータ)の詳細
| 引数名 | 例 | 説明 |
|---|---|---|
player_id | 22024 | 選手の一意のID(players.find_players_by_full_name() などで取得) |
season | "2024-25" | 対象のシーズン。NBA APIでは "YYYY-ZZ" の形式を使用 |
season_type_all_star | "Regular Season" | "Playoffs"(プレイオフ)や "Pre Season"(プレシーズン)も可 |
最後のdf = gamelog.get_data_frames()[0]で、エンドポイントから取得したデータを、pandasのDataFrameとして整形しています。こうすることで、表形式でデータを取得できます。
なんで最後に[0]をつけるのか疑問に思った方もいるでしょうが、nba_api で playergamelog などの エンドポイント(endpoint) を使うと、データは HTML形式のテーブル構造で取得され、get_data_frames() は リスト型 を返します。[DataFrame1, DataFrame2, …]みたいな感じで複数のテーブル(pandasのDataFrame)が入ったリストになります。実際に欲しい「本体データ(メインの試合ログ)」は、
このリストの1番目(インデックス0) に入っているのが一般的です。なので[0]を最後につけて、一番最初のDataFrameを指定しています。※Pyhonのカウントは0からです。
それでは中身を見てみましょう。
print(df.head())結果は以下になります。
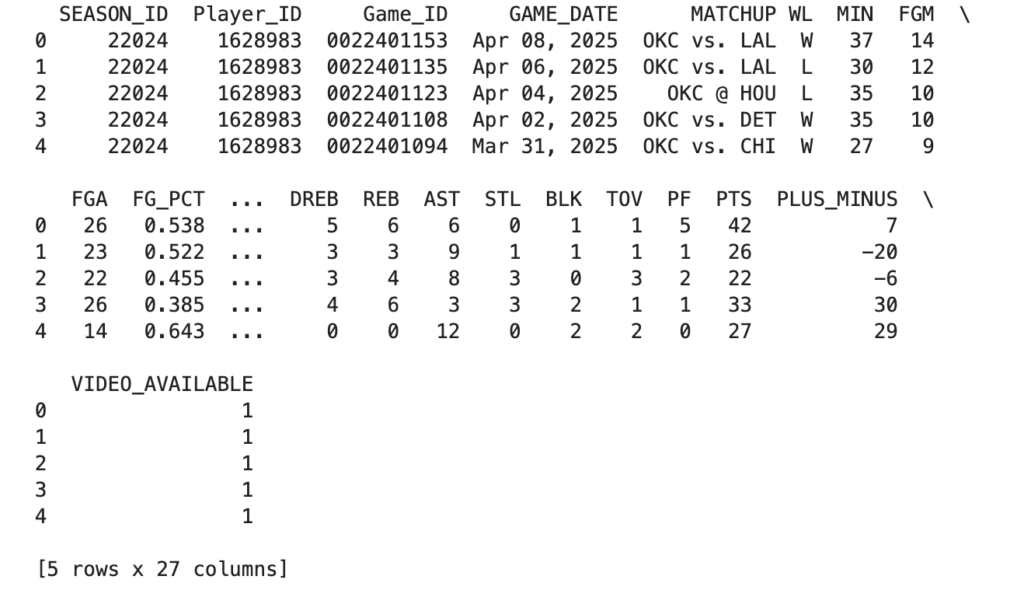
最後に[5 rows x 27 columns]とありますが、27項目のデータが見れるようです。GAME_DATEを見てみると、レギュラーシーズンの最終戦のデータになっているので直近の試合のデータから出てくるようです。ちなみにprint(df.tail())で末尾から5行を確認できます。
次にデータの数を確認してみましょう。
print(len(df))関数len()で行数を取得することができます。()の中にdfを入れることで、dfというデータセットの行数を取得しました。
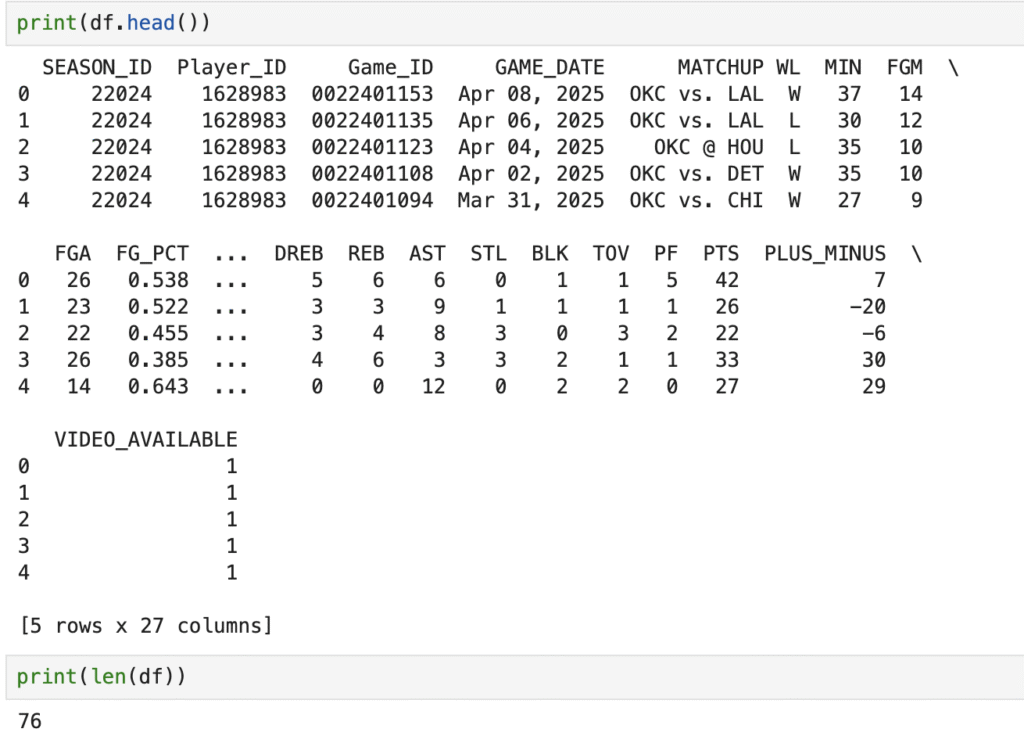
全部で76行あると出ました。NBAの試合数は1シーズン82試合数ですが76試合と出るのは、エンドポイントplayergamelogには出場試合のみ含まれるからです。シェイは今シーズン76試合に出場し、6試合のみ欠場してます。
シェイの2024-25レギュラーシーズン出場試合76試合のスタッツを取り出すことができました。ではこれを用いて代表値を求めていきましょう。今回は得点(PTS)を主に扱っていきたいと思います。
平均(mean)
平均は、全部の合計 ÷ 件数でした。例えば1試合の平均得点を求めたいと思ったら、シーズンの合計得点 ÷ 出場試合数です。
PTS_mean = df['PTS'].sum() / len(df)
print(round(PTS_mean,1))以上を実行すると「32.7」と出力されます。シェイは平均32.7得点でシーズン得点王に輝いてます。
df[‘PTS’].sum() で得点(PTS)の列を合計(sum)するという意味です。それをデータ数(行数)で割った数値をPTS_meanに代入しています。round(PTS_mean,1)はPTS_meanを小数点1桁まで表示するようにします。小数2桁目を四捨五入していると思いがちですが、round()は四捨五入ではないので気になった方は調べてみてください。
ただ、pandasを用いればこのような計算式を書かなくても大丈夫です。pandas関数を使用することでこの計算式を省略できます。
PTS_mean_pandas = df['PTS'].mean()
print(round(PTS_mean_pandas,1))
pandas関数の .mean() で平均を求めることができます。実行すると「32.7」になり、先ほどの計算式で求めた数値と合っていることが確認できます。
中央値(median)
中央値はデータを小さい順に並べたときの真ん中の値でした。まずは得点を小さい順から順番に並べてみます。
sorted_df = df.sort_values(by = 'PTS', ascending = True).reset_index(drop=True)
print(sorted_df.head())並び替えについては、前回の6:pandasの基礎②:並べ替え、抽出、集計を参照してください。.reset_index(drop=True)はpandasのSeriesやDataFrameのインデックス(行番号)を振り直すためのメソッドです。デフォルトでは古いインデックスも残りますが、drop=Trueとすることで古いインデックスを削除します。
中央値は、行数が奇数個か偶数個かによって求め方が変わります。
奇数個なら → 中央1個 例:7個 → 4番目(インデックス 3)
偶数個なら → 中央2個の平均 例:76個 → 38番目と39番目(インデックス 37と38)
今回は76行ありますので、真ん中の値は38個目と39個目の数値(インデックス 37と38)の平均です。
DataFrameから38個目と39個目の数値を取り出すのは以下のようにします。
index_38 = sorted_pts["PTS"].loc[37]
index_39 = sorted_pts["PTS"].loc[38]
print(f"38行目:{index_38}")
print(f"39行目:{index_39}")
median = sorted_pts["PTS"].loc[37:38].mean()
print(f"中央値:{median}")print(f”…”)は「f文字列(f-string)」と呼ばれる書き方で、Pythonで文字列の中に変数を埋め込むときに使います。上記のように、print(f”…”)の…の部分で、{}で囲んだ変数を変数の出力と文字列を組み合わせることができます。.loc[] は pandas の ラベルベースのインデックスアクセス方法です。37と38というインデックスのラベルを指定しました。似たものとして、iloc[]がありますが、この例だと使い分けの説明が難しいので、別の章で解説します。
結果は以下のように出力されます。

平均点と近い結果になっていることが確認できます。
ご察しの通りこのような方法を取らなくても、pandas関数で簡単に出力できます。
PTS_median_pandas = df['PTS'].median()
print(round(PTS_median_pandas,1))pandas関数の .median() で中央値を求めることができます。結果は32.0になります。
最頻値(median)
最頻値は最もよく出てくる値でした。シェイが今シーズン最も多く残した得点とも言えますね。もちろんpandan関数を使えばすぐに求められるのですが、勉強のためにpandas関数を使わないやり方でやってみましょう。
# 各得点(PTS)の試合数をカウントし、DataFrame化
count_per_PTS = df.groupby('PTS')['Game_ID'].count().reset_index()
# 列名をわかりやすく変更
count_per_PTS.columns = ['PTS', 'count']
# 件数が多い順に並び替え
sorted_count_per_PTS = count_per_PTS.sort_values(by='count', ascending=False).reset_index(drop=True)
print(sorted_count_per_PTS)基本的に今まで学習したものの組み合わせです。df.groupby(‘PTS’)[‘Game_ID’].count().reset_index()で、reset_index()をつける理由は、count_per_PTS は Series なので、[‘PTS’, ‘count’]という列名を付けようとするとエラーになります。Series には複数の列を持たせられないからです。よって、reset_index()をつけることでDataFrameに直してます。試合数のカウントに用いる変数として、なんでもいいのですがここでは’Game_ID’を使用しています。groupby() を用いて得点(PTS)ごとに試合数を集計し、sort_values() を使って試合数が多い順に並び替えています。これにより、今シーズンのシェイが「最も頻繁に記録した得点」から「最も稀に記録した得点」までを、順番に確認することができます。結果は以下の通りです。
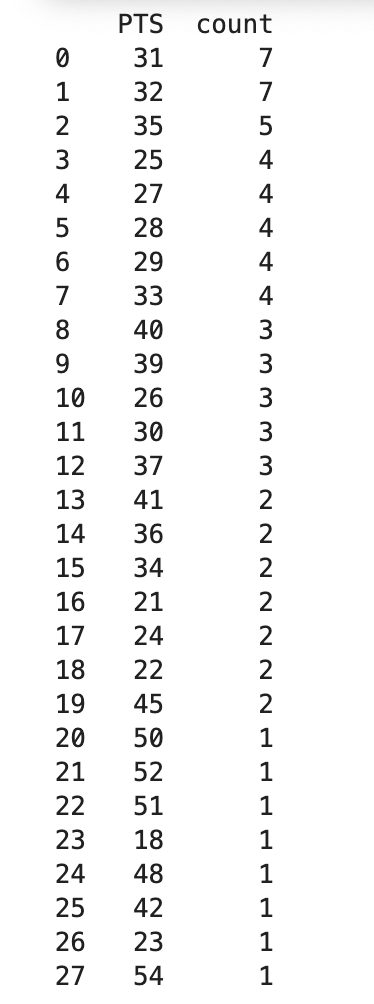
最頻値は31点と32点で各7回ずつですね。やはり平均と近い値になっています。こう見ると、20点未満は18点の1回のみという異次元の活躍が確認できます。
では、pandas関数で確認していきましょう。
PTS_median_pandas = df['PTS'].median()
print(round(PTS_median_pandas,1))pandas関数の .mode() で最頻値を求めることができます。結果は以下になります。

まとめ
| 代表値の種類 | pandas関数 | 特徴 |
|---|---|---|
| 平均 | .mean() | 最もよく使われる指標 |
| 中央値 | .median() | 外れ値に強い・実感に近いことも |
| 最頻値 | .mode() | パターンが多い時に使える |
次回はデータの可視化について学んでいきましょう。